
OnBeacon needed to build an AI-first product that could turn slow, subjective design reviews into fast, actionable feedback.

Built an AI-native, multi-agent platform that analyzes UI designs, validates insights, and delivers real-time, brand-aligned recommendations.

Reduced time from insight to action from weeks to minutes, drove 19K+ users with 30% MoM growth, and supported $1.3M pre-seed funding.

AI Design Reviewer - Enhance UI/UX, Accessibility, CTA & Copy - Fountn.design
I tested 4 plugins that analyze UX with artificial intelligence - Cinthia Venâncio

I have worked with some of the best AI talent in the world at companies like Siri and Apple. When it came to building an AI team for my own startup DesignPro (now onBeacon), I relied on Tintash to find me talent with excellent research, engineering and communication skills. I am beyond impressed with their talent pool and team's ability to do exceptional work at an affordable price.

Mohammad Abdoolcarim
Co-Founder, onBeacon
Design reviews were slow, inconsistent, and impossible to scale
Picture a typical design review before onBeacon. A product team opens a Figma file, shares a screen, and spends an hour going back and forth. One designer flags the visual hierarchy. Another disagrees. A third raises an accessibility concern that contradicts the first. The meeting ends with a list of feedback items, most of them subjective, some of them in conflict with each other. Then someone has to turn that into actual design changes. That process takes another week.
For fast-moving product teams, this was simply the norm. The quality of a design review depended entirely on who was in the room and how much time they had. There was no way to make the output consistent across reviewers, no mechanism to grow throughput without adding people, and no path from feedback to implementation that did not involve another round of meetings.
onBeacon set out to change that. The goal was a platform that could analyze any UI design in real time, surface structured evidence-backed findings, and go one step further by generating concrete prototypes showing teams exactly what a recommended change would look like applied to their actual work. Not abstract feedback. Something a designer could act on in the same session. They needed a technical partner who could own the architecture and build something production-ready from scratch.
A production multi-agent architecture of 30-40 specialized agents, with Claude handling the most reasoning-intensive workloads
Tintash owned the system architecture, AI orchestration layer, model evaluation framework, backend implementation, and deployment infrastructure, building the platform from the ground up. The platform has been in continuous production use for two years, evolving through multiple generations of AI models. It has active users across a Figma plugin, Web Dashboard, and a managed service where onBeacon’s designers moderate AI-generated analysis for enterprise clients. Human reviewers remain in the loop for enterprise engagements, validating AI-generated recommendations before delivery to customers.
The platform routes each design through a production multi-agent system composed of 30–40 specialized agents running in parallel. Each agent evaluates a specific dimension of quality: layout, typography, accessibility, CTA clarity, brand alignment, and other categories. This decomposition allows individual dimensions to be independently benchmarked, tuned, and upgraded without affecting the rest of the system. A resolution agent then consolidates findings across all agents into a single coherent output, handling cross-agent conflicts the way a senior reviewer would.
The platform is multi-model by design. Each agent is benchmarked independently and model selection follows what performs best for that specific task. Models are evaluated on latency, cost, visual understanding, reasoning quality, and actionability of outputs before assignment to production workloads. Visual inspection agents, reading color values, layout structure, and typography, run on GPT-4o where structured pattern recognition is the primary requirement. For tasks that demand both image understanding and complex multi-step reasoning at the same time, the platform uses Claude’s models.
Where Claude Opus powers the platform's highest-value reasoning workloads
Claude Opus powers two of the platform's highest-value reasoning workloads: UX Critique and Prototype Generation. The selection came out of direct model comparison testing. Claude was selected because it consistently outperformed alternatives on traceable reasoning, grounding recommendations in established UX principles, and generating actionable outputs that designers could implement without additional interpretation.
Most models evaluated could identify surface-level design issues but struggled when the task required grounding analysis in established UX, cognitive psychology, and human-computer interaction principles. Getting to specific, traceable reasoning rather than generic observations turned out to be the hard part.
Claude Opus performed significantly better on that requirement. The analysis it produced was grounded in established principles, the reasoning was traceable, and the output was structured, evidence-backed, and directly actionable.
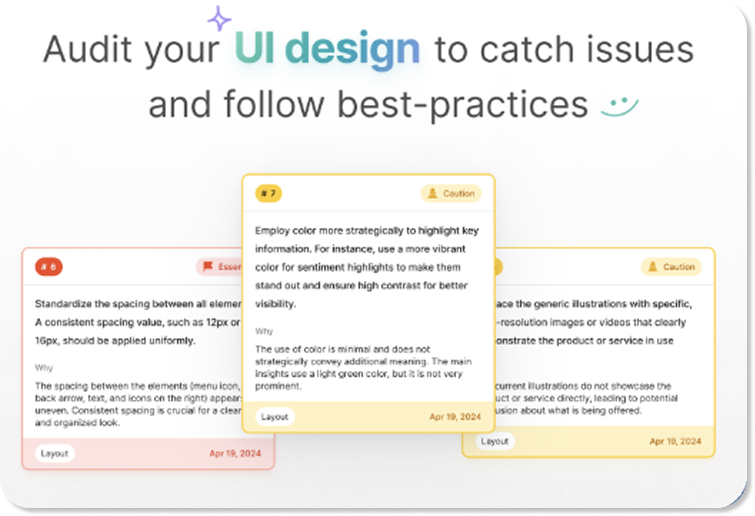
UX Critique
The UX critique layer runs on Claude Opus. It evaluates user flows and design decisions against established UX, cognitive psychology, and human-computer interaction principles, holding context across a full design system rather than responding to isolated elements. The output is the kind of structured, reasoned critique that previously required a senior designer and a synchronous review session. It is now available on demand, consistently, at any scale.
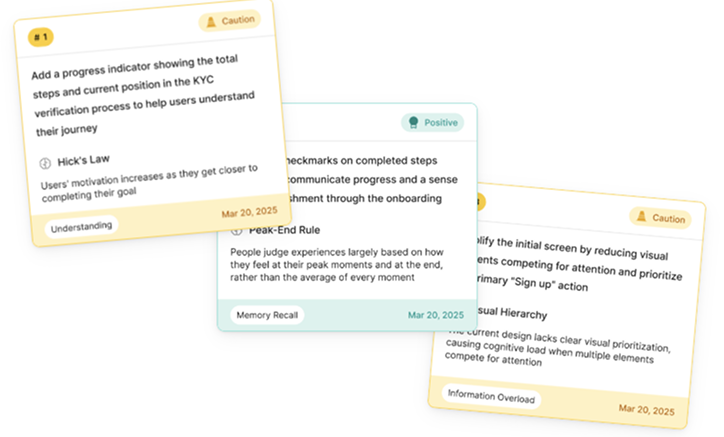
UX Critique & Onboarding Audit

Prototype Generation
After surfacing findings, the platform uses Claude Opus to generate design variants and visual prototypes showing teams exactly what a recommended change would look like applied to their actual design. A finding about visual hierarchy is easy to dismiss. A Claude-generated prototype showing the corrected layout, in context, applied to the team's actual work is not.
For simpler pipeline tasks such as restructuring outputs and formatting analysis for the front end, the platform uses Claude Sonnet, where the task does not require the same reasoning depth and a lighter model performs well. The team's approach to model selection is to find the model best suited to the job and re-evaluate as new versions ship. As Anthropic models have raised the ceiling on reasoning and image understanding, Claude's role in the pipeline has grown. The roadmap includes expanding Claude's role across additional analytically demanding workloads within the system.
Two years in production and in use by design teams at some of the world's largest organizations
onBeacon has been in sustained production for two years. Design teams at global organizations including ByteDance, Salesforce, Siemens, Dubai Govtech Agency, and Singapore Govtech use the platform. AI recommendations have been implemented in live product roadmaps and active sprints.
- 19,000+ product/design users acquired organically
- 30% month-over-month growth in signups
- Time from design insight to implementation reduced from weeks to minutes
- $1.3M pre-seed raised, with the platform as the core proof point
- AI-generated design recommendations implemented in live product roadmaps and sprints
The design review process that once required a room full of people, a shared screen, and a week of follow-up now runs in minutes. Findings are grounded in principles, prototypes are ready to act on, and the output is consistent regardless of who is doing the reviewing.
